Multi Paxos
前言
Google 在设计 Chubby 时,希望构建一个能够提供分布式锁(Distributed Lock)、Master 选举(Leader Election)以及元数据存储(Metadata Storage)能力的基础设施。后续的 GFS 和 Bigtable 等核心系统均建立在 Chubby 之上。
Chubby 的早期版本采用商用数据库 3DB 作为底层存储引擎。然而在生产环境中,3DB 暴露出了复制错误(Replication Bugs)、一致性语义不明确等问题。更重要的是,其复制协议缺乏严格的理论证明,无法从理论上保证系统状态的一致性。
为了解决这一问题,Google 决定基于 Paxos 共识算法重新设计底层存储系统。然而,在实际工程实践过程中,研究人员发现:
理论上的 Paxos 算法与生产级分布式系统之间存在巨大的实现鸿沟(Gap Between Theory and Practice)。
因此,Google 在保持 Paxos 安全性不变的前提下,引入了一系列工程化扩展和优化,最终构建出了能够在生产环境稳定运行的 Chubby 系统。
容错
构建容错系统最常见的方法之一,是通过共识算法保证多个副本之间的数据一致性。
通过不断对一系列输入值重复执行共识算法,可以在所有副本上维护一份完全一致的复制日志(Replicated Log)。如果日志中的值表示对某个数据结构的操作,则所有副本按照相同顺序执行这些操作后,将得到完全相同的状态。
例如,当日志记录的是数据库操作时:
1 | |
所有副本按照相同顺序重放这些操作后,最终将获得一致的数据库内容。
这一思想被称为:
1 | |
即:
共识协议负责保证日志一致性,而状态机负责执行日志,从而保证系统状态一致性。
Chubby
Chubby 通过副本复制实现容错。一个典型的 Chubby Cell 由五个副本组成,每个副本运行相同的代码,并部署在独立的服务器上。
每一个 Chubby 对象(例如锁、目录或文件)都会作为数据库中的一条记录存储,而真正被复制的是整个数据库。
在任意时刻,这五个副本中有且仅有一个被选举为Master。
Chubby 客户端(例如 GFS 和 Bigtable)始终通过 Master 提供服务。如果客户端连接到非 Master 副本,该副本会返回当前 Master 的地址,客户端随后重新连接至 Master。
当 Master 发生故障时,系统会自动选举新的 Master。由于所有副本都维护着一致的数据库副本,因此新的 Master 可以在本地状态基础上继续提供服务,从而保证系统状态的连续性。
Chubby 的整体架构如下所示:
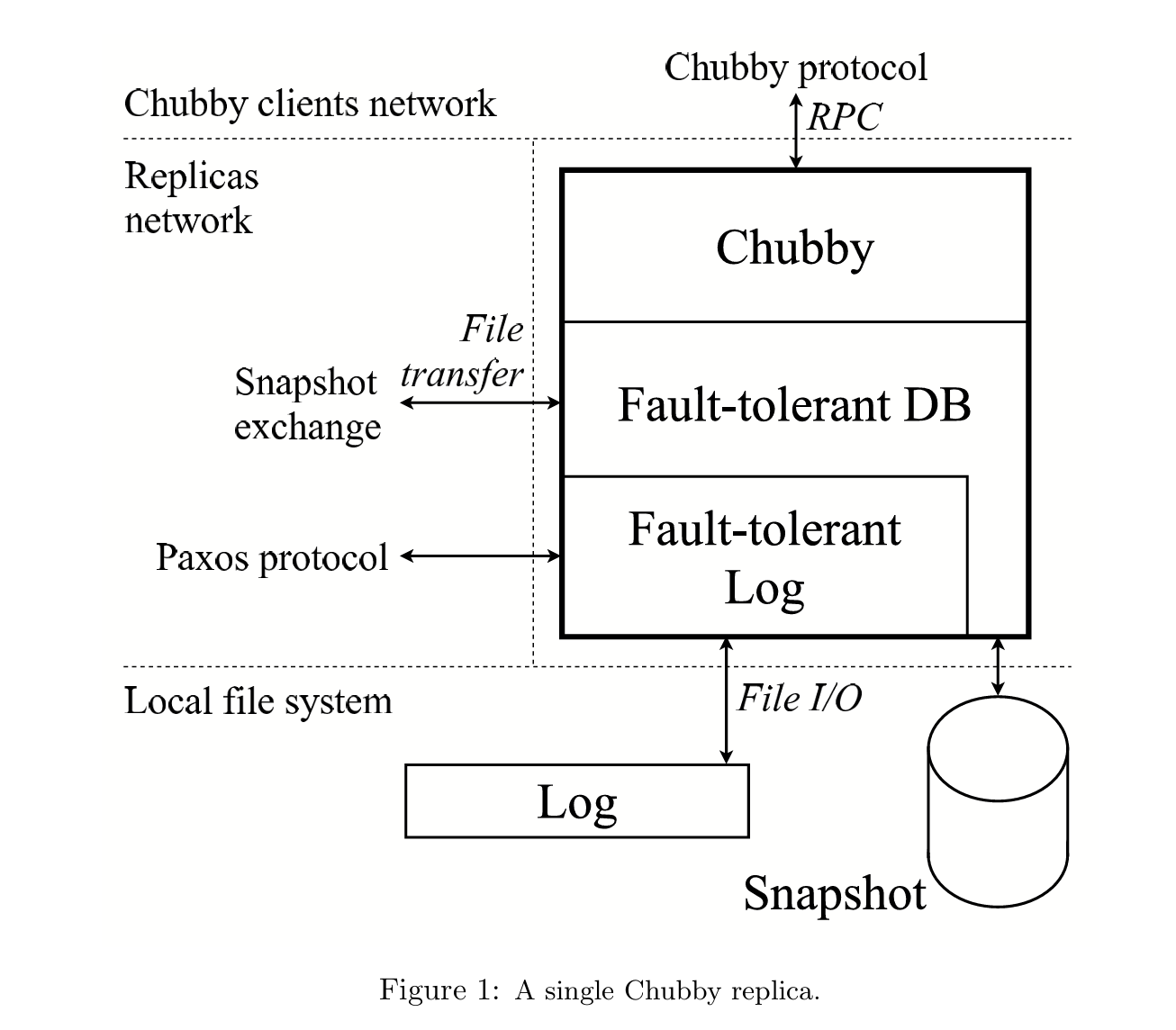
在协议栈最底层,是基于 Paxos 的容错复制日志层(Fault-Tolerant Replicated Log)。
每个副本都维护着一份本地日志副本。Paxos 被不断重复执行,以确保所有副本最终拥有完全一致的日志序列。
副本之间通过 Paxos 协议进行通信。
协议栈的上一层是容错数据库层(Fault-Tolerant Database)。
每个副本都维护数据库的本地副本,数据库由以下两部分组成:
- Snapshot(快照)
- Replay Log(重放日志)
新的数据库操作首先提交到复制日志层。
当某个日志条目在副本间达成共识后,该操作会被应用到各副本的本地数据库中。
在最顶层,Chubby 使用该数据库保存锁、文件和系统元数据等状态信息,并通过 Chubby 协议向客户端提供服务。
Chubby 的容错日志结构如下:
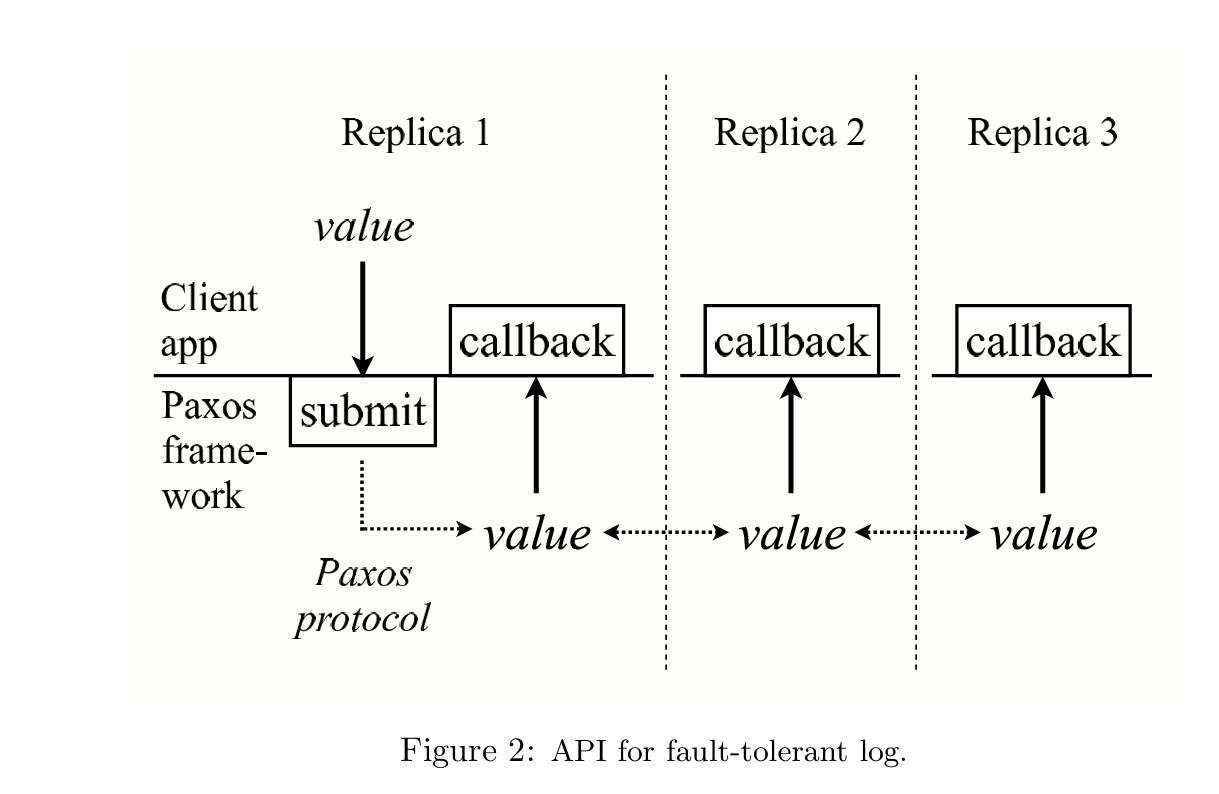
它提供一个向日志提交新值的接口。
当某个值被成功写入容错日志(即在集群中被 Chosen)后,系统会在每个副本上触发回调函数(Callback),并将该值传递给应用程序。
这里的 Callback 并不是回调客户端(Client),而是回调运行在各副本上的状态机应用程序。
1 | |
总体而言:
Paxos 负责保证所有副本拥有完全一致的日志;应用程序通过
onCommit()按照相同顺序执行日志,从而保证所有副本最终达到一致状态。
Basic Paxos
Paxos 是一种用于解决非拜占庭故障环境下一致性问题的共识算法。
系统中的副本可能发生:
- 节点崩溃(Crash)
- 节点恢复(Recovery)
- 网络延迟(Delay)
- 网络丢包(Loss)
- 网络分区(Partition)
同时,每个副本均拥有能够跨越崩溃保存状态的持久化存储。
Paxos 保证:
如果最终有超过半数的副本持续存活并能够互相通信,则系统最终能够就某个被提议的值达成一致。
在 Chubby 中,被共识的对象不是单个业务值,而是复制日志中的下一条日志记录(Log Entry)。
该算法可以抽象为三个阶段:
- 选举协调者(Coordinator)。
- 协调者提出待共识的值。
- 多数派接受后宣布提交(Commit)。
由于故障可能发生,上述过程可能被重复执行。
为了保证一致性,Paxos 允许多个副本同时尝试成为协调者。
多个协调者可能同时存在:
1 | |
并且可能提出不同的值。
为了解决这一问题,Paxos 引入了两项关键机制:
- 对协调者进行全局排序(Proposal Number)。
- 限制协调者选择值的自由度。
协调者排序机制通过 Proposal Number 实现。
每个副本记录:
1 | |
当副本尝试成为协调者时,会生成一个全局唯一且递增的 Proposal Number:
1 | |
并向所有副本发送提议。
如果多数派副本返回:
1 | |
则该副本获得当前轮次的协调权。
Promise 的含义为:
承诺未来不会再接受编号小于 n 的提案。
为了保证已经达成的共识不会被后续提案破坏,Promise 消息还需要返回:
1 | |
即:
1 | |
新的协调者必须从收到的所有回复中选择 Proposal Number 最大的那个值继续提议。
例如:
1 | |
则新的协调者必须继续提议:
1 | |
而不是自由选择新的值。
这一规则构成了 Paxos 安全性的核心基础。
Multi-Paxos
在实际系统中,Paxos 很少用于对单个值达成共识,而是被用于维护一条持续增长的复制日志。
最直接的实现方式是:
1 | |
即:
每个日志槽位(Slot)对应一次独立的 Paxos 实例。
因此,向日志提交一个值,本质上就是执行一次新的 Paxos 实例。
在 Multi-Paxos 中,一些较慢(Lagging)的副本可能没有参与最近的 Paxos 实例,因此需要通过 Catch-up 机制追赶最新进度。
每个副本都会维护本地持久化日志(Persistent Log),用于记录所有 Paxos 状态变化。
当副本崩溃恢复后,可以通过重放日志恢复崩溃前状态。
这些日志同样用于帮助落后副本追赶最新进度。
Basic Paxos 的一个严重性能问题在于:
1 | |
每个阶段都需要持久化。
因此一次共识可能需要五次磁盘刷盘(Disk Flush)。
在低延迟网络环境中,磁盘刷盘时间往往会成为整个系统的主要性能瓶颈。
为了解决这一问题,Multi-Paxos 引入了著名优化:
当 Coordinator 未发生变化时,可以省略后续实例中的 Prepare/Promise 阶段。
即:
1 | |
只在 Leader 切换时执行一次 Prepare。
Google 将长期稳定存在的 Coordinator 称为:
1 | |
通过该优化,每个 Paxos 实例只需要一次关键写盘操作,并且多个副本可以并行执行写盘。
此外,为提高吞吐量,系统还支持:
1 | |
即将多个客户端请求打包到同一个 Paxos 实例中统一提交,从而提高整体吞吐能力。
现实挑战
处理硬盘损坏
Paxos 的经典理论模型假设:
持久化存储(Persistent Storage)是可靠的。
然而在真实生产环境中,这一假设并不总是成立。
副本(Replica)可能因为以下原因发生磁盘损坏:
- 磁盘介质故障(Media Failure)
- 文件系统损坏(Filesystem Corruption)
- 运维误操作(Operational Mistake)
- 数据误删除(Accidental Deletion)
当副本丢失持久化状态后,它将忘记自己曾经做出的:
1 | |
记录。
这意味着它可能违反过去已经做出的承诺(Promise),从而破坏 Paxos 的安全性假设。
为了检测磁盘损坏,Chubby 采用了两种机制:
校验和检测
对于每个持久化文件,系统都会维护对应的校验和(Checksum)。
当文件内容发生意外修改时,可以通过校验和验证发现数据损坏。
空磁盘检测
部分故障并不会导致文件内容损坏,而是导致整个磁盘变为空。
例如:
1 | |
或者:
1 | |
此时系统无法区分:
1 | |
和:
1 | |
为了解决这一问题,Google 在 GFS 中记录节点身份标记。
如果某副本重新启动时发现:
1 | |
则可以判断该节点发生了磁盘损坏。
状态重建
当检测到磁盘损坏后,该副本不会立即参与投票。
而是以:
1 | |
身份加入集群。
即:
- 接收日志
- 执行 Catch-up
- 恢复状态
但是不会回复:
1 | |
消息。
只有当其完成状态同步,并观察到一个完整的新 Paxos 实例后,才重新获得投票资格。
这样能够确保:
它不会因为遗忘历史状态而违反过去做出的承诺。
主节点租约
基础 Paxos 存在一个容易被忽略的问题:
读取操作也必须经过共识协议。
原因在于:
某个旧 Master 可能已经失去领导权。
例如:
1 | |
发生网络隔离。
随后:
1 | |
被成功选举出来。
如果客户端仍然向旧 Master A 发起读取请求,则可能读取到过期数据(Stale Data)。
因此,理论上:
1 | |
也需要经过 Paxos 进行线性化(Linearization)。
然而在实际系统中:
1 | |
如果每次读取都执行 Paxos,共识层将成为系统瓶颈。
为了解决这一问题,Chubby 引入了:
1 | |
机制。
其核心思想是:
在租约有效期间,保证不会出现新的合法 Master。
因此:
1 | |
可以直接基于本地状态提供读取服务。
无需经过 Paxos。
在实现上:
所有副本都会隐式向当前 Master 授予租约。
租约期间:
1 | |
拒绝处理来自其他节点的:
1 | |
请求。
因此:
1 | |
无法获得多数派支持。
为了维持租约:
Master 会周期性提交:
1 | |
日志条目。
用于刷新租约时间。
同时:
1 | |
从而容忍一定程度的时钟漂移(Clock Drift)。
这一思想后来深刻影响了:
- ZooKeeper Lease
- Raft Lease Read
- ReadIndex
- Spanner Leader Lease
等现代分布式系统设计。
Master Churn 问题
Multi-Paxos 的性能建立在:
1 | |
的前提之上。
然而网络故障可能导致:
1 | |
短暂失联。
此时集群可能选举出:
1 | |
作为新的 Master。
随后:
1 | |
重新连接。
由于它可能拥有更高的 Proposal Number,因此又重新夺回领导权。
之后再次失联。
再次被替换。
形成:
1 | |
的循环。
这种现象称为:
1 | |
即:
Leader 频繁切换。
Master Churn 会导致:
- Leader 不断变更
- 客户端频繁重连
- Paxos Prepare 阶段频繁执行
- 系统吞吐量下降
为了解决这一问题:
Google 的实现允许当前 Master 定期主动提升自己的 Proposal Number。
即主动执行:
1 | |
刷新自身领导权。
从而减少 Leader 抖动现象。
纪元号(Epoch Number)
考虑如下场景:
1 | |
客户端发出请求。
在请求执行过程中:
1 | |
失去领导权。
随后:
1 | |
当选。
之后:
1 | |
又重新成为 Master。
此时:
客户端请求横跨了多个 Master 周期。
系统必须保证:
该请求不能继续执行。
否则可能产生一致性问题。
Chubby 引入:
1 | |
机制。
定义如下:
当且仅当某个副本在两个请求之间持续担任 Master 时,两次读取到的 Epoch Number 才相同。
Epoch 被存储于复制数据库中:
1 | |
每次 Master 切换:
1 | |
所有数据库操作都携带 Epoch。
如果发现:
1 | |
则直接:
1 | |
终止请求。
从而保证请求执行期间 Leadership 没有发生变化。
成员组管理
实际系统无法假设:
1 | |
因为:
- 节点可能永久损坏
- 节点可能扩容
- 节点可能下线维护
因此需要支持:
1 | |
即:
1 | |
虽然理论上:
Paxos 本身也可以对配置变更达成共识。
但是在实际系统中:
1 | |
等机制同时存在时,
成员组管理会变得异常复杂。
Google 在论文中指出:
现有文献对这一问题描述不足,大量工程细节需要自行设计和验证。
快照
复制日志会持续增长:
1 | |
这会导致两个问题:
- 无限增长的存储开销。
- 无限增长的恢复时间。
因此需要引入:
1 | |
机制。
快照保存:
1 | |
而非:
1 | |
恢复流程变为:
1 | |
而不是:
1 | |
快照由应用层负责生成。
Paxos 框架本身并不了解:
1 | |
等具体业务状态。
因此:
只有应用层知道如何生成快照。
当应用通知 Paxos:
1 | |
后,
Paxos 可以安全删除:
1 | |
之前的日志。
这一过程称为:
1 | |
数据库事务
Chubby 对数据库功能需求并不复杂。
主要支持:
- Insert
- Delete
- Lookup
- Compare-And-Swap(CAS)
- Iteration
数据库采用:
1 | |
结构实现。
其中:
1 | |
需要保证原子性。
例如:
1 | |
不能被其他操作插入。
Chubby 的做法是:
将整个 CAS 操作封装为:
1 | |
提交给共识层。
例如:
1 | |
作为单条日志进入 Paxos。
由于 Paxos 保证:
1 | |
因此:
1 | |
天然具有原子性。
Google 进一步发现:
这一机制实际上已经具备了轻量级事务(Transaction)的基础能力。
无需实现复杂数据库事务系统,
即可获得足够强的一致性保证。
总结
《Paxos Made Live》最重要的贡献并不在于提出新的共识算法,而在于揭示:
从理论 Paxos 到生产级系统之间存在大量未被论文覆盖的工程问题。
这些问题包括:
- 磁盘损坏(Disk Corruption)
- 成员变更(Reconfiguration)
- 主节点租约(Master Lease)
- 日志追赶(Catch-up)
- 快照(Snapshot)
- 数据库事务(Transaction)
- 测试与运维(Testing & Operations)
Google 的实践表明:
构建一个正确且可运行的 Paxos 系统,其难度远远超过理解 Paxos 算法本身。
论文最后总结了三点重要经验:
- Paxos 理论与实际系统之间存在巨大的实现鸿沟;
- 容错计算领域缺少易于工程实现的工具链;
- 测试是构建容错系统不可或缺的组成部分。
《Paxos Made Live》因此被广泛认为是:
从理论共识协议迈向工业级分布式系统的重要里程碑。
它也深刻影响了后续的:
- ZooKeeper
- Spanner
- etcd
- TiKV
- CockroachDB
等现代分布式系统的设计理念。