Java基础数据结构
数据结构
1.基本数据类型
Java中基本数据类型有8种:short(2 Byte), int(4 Byte), float(4 Byte) , long(8 Byte), double(8 Byte), byte(1 Byte), boolean(1 bit), char(1 Byte)
| 数据类型 | 关键字 | 大小 | 取值范围 | 默认值 | 包装类 |
|---|---|---|---|---|---|
| 字节型 | byte | 1字节 | -128 ~ 127 | 0 | Byte |
| 短整型 | short | 2字节 | -32768 ~ 32767 | 0 | Short |
| 整型 | int | 4字节 | -2³¹ ~ 2³¹-1 | 0 | Integer |
| 长整型 | long | 8字节 | -2⁶³ ~ 2⁶³-1 | 0L | Long |
| 单精度浮点 | float | 4字节 | ±3.4^38 | 0.0f | Float |
| 双精度浮点 | double | 8字节 | ±1.7^308 | 0.0d | Double |
| 字符型 | char | 2字节 | ‘\u0000’ ~ ‘\uffff’(UTF-8) | ‘\u0000’ | Character |
| 布尔型 | boolean | 1位 | true/false | false | Boolean |
浮点数精度
浮点数采用IEEE754存储,浮点数无法精确表示。
1 | |
因此进行浮点数比较是否相等时必须使用差值小于某一值
1 | |
float 与 double
所有单独出现的小数均默认为double类型,如果要定义float类型,后面必须加f后缀。
1 | |
转换
隐式转换
小类型转化为大类型不会丢失精度。
1 | |
强制转换
大类型强制转为小类型,可能存在精度丢失。
1 | |
数据装箱、拆箱
基本概念
装箱:基本类型 → 包装类型
拆箱:包装类型 → 基本类型
1 | |
运算时自动装箱、拆箱
JDK1.5+的新特性:int 可以直接和Integer类型直接进行运算,自动进行intValue()和valueOf()
1 | |
缓存机制(IntegerCache)
当Java对某些特定范围的整型数据进行自动装箱时,它不会每次都创建一个新的对象,而是会从一个预先创建好的缓存数组中直接获取对应的包装类对象。
例如:对于Integer来说,其缓存范围在-128~127(通常情况下这个范围内的数据使用频率较高),意味着在创建该范围内的对象时,其使用的对象将会重用同一缓存内的对象。
1 | |
而当
1 | |
对于一个Integer类型的值进行运算,其会先拆箱接着装箱
1 | |
Integer类型是
immutable的,一旦创建值就不能改变,想要改变必须先拆箱后装箱。Integer是一个类,而int是基本数据类型,因此Integer可以等于
null,而int不行。=运算会比较JVM中的地址,而equals()则有其不同的重写方法,通常情况下会比较对象所含的值。
常用方法
valueOf()
参数为基本数据类型,返回包装类对象;
1 | |
参数为String字符串(Character类没有以String为 参数的该方法),返回包装类对象;
1 | |
parseInt()
参数为字符串,返回基本数据类型;
1 | |
2.数组
int[]
数组是用于存储固定大小、相同类型元素的线性数据结构。其继承于Object类型,拥有Objet.toString(),Object.equals(),和Obejct.hashCode()等方法,并且保存在JVM的堆中。
数组的声明方式如下:
1 | |
由于数组一旦声明长度就不可变,其以连续空间的形式存储在堆中,因此在随机访问时,可以通过下标×偏移量加首地址的方式计算出目标地址,随机访问的时间复杂度为O(1)。
List
List
Collection<E>: 所有集合类(如 Set, List, Queue)的根接口,定义了添加、删除、遍历等基本操作。Iterable<E>:Collection的父接口,意味着所有List都可以使用 for-each 循环进行迭代。
1 | |
ArrayList
ArrayList的底层结构是动态数组,ArrayList 不是线程安全的,在多线程环境下需要同步。
如何创建一个线程安全的List:
1 | |
LinkedList
LinkedList的底层结构是双向链表,同样不是线程安全的,在多线程环境下需要同步。
LinkedList可以作为Queue和Dueue的底层结构。
1 | |
| 特性 | ArrayList | LinkedList |
|---|---|---|
| 底层结构 | 动态数组 | 双向链表 |
| 随机访问 | O(1) | O(n) |
| 头部插入 | O(n) | O(1) |
| 尾部插入 | 均摊O(1) | O(1) |
| 中间插入 | O(n) | O(n) |
| 内存占用 | 较小(连续内存) | 较大(每个元素含两个指针) |
| 缓存友好 | 是(CPU在取值的时候可以预取) | 否 |
如何选择 ArrayList 和 LinkedList?
根据具体场景:如果需要频繁随机访问,选择ArrayList;如果需要频繁在头部插入删除,选择LinkedList。大多数情况下ArrayList是更好的选择,因为CPU缓存友好,实际性能往往优于LinkedList。
stack
基于vector实现,同样有性能问题,推荐使用ArrayDueue作为栈。
1 | |
CopyOnWriteArrayList
写时复制(COW)
写的时候加锁并复制到新数组:
1 | |
适用场景?
读多写少(读操作不需要锁,直接访问数组)
写操作性能较差(需要复制整个数组)
toCharArray()
特性
快速失败
1 | |
Iterator 在被创建时,会记录下集合的当前修改次数(modCount)。当你通过 list.add("b") 修改了 list 的结构后,这个修改次数会增加。当迭代器调用 it.next() 方法时,它会检查当前集合的修改次数是否与它在创建时记录下来的修改次数一致。一旦不一致,就会抛出ConcurrentModificationException,快速失败
子列表视图
1 | |
subList并非一个新的对象,而是对原对象的一个局部引用
多维数组
Java支持多维数组,但实际上是数组的数组。例如,int[][]是一个一维数组,其中的每个元素又是一个 int[]数组。这意味着多维数组可以是不规则的(每行的长度可以不同)。
如何创建一个不规则的多维数组:
1 | |
Java中的多维数组的地址分配更接近于下图:
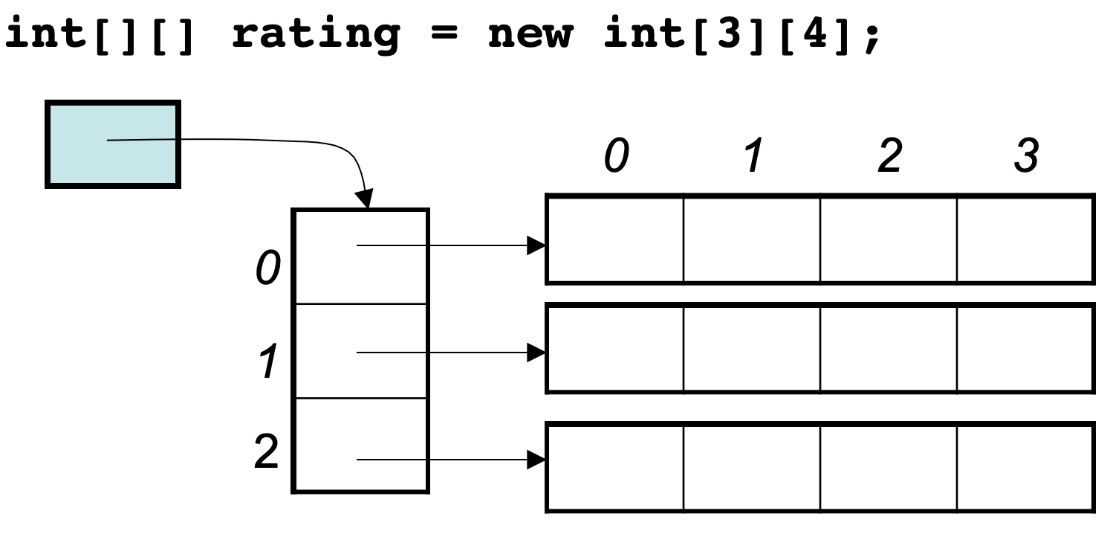
在C中int[][] 的大小是固定的,其在堆上连续分配,而JVM中int[0]的地址和int[1]的地址并非连续。
常用方法
Arrays.sort(arr): 排序(双轴快排)。
Arrays.sort(arr, Comparator.reverseOrder()):由大到小排序。
Arrays.binarySearch(arr, key): 二分查找(数组必须已排序)。
Arrays.fill(arr, value): 填充值。
Arrays.equals(arr1, arr2): 比较两个数组的内容是否相等(深层次比较元素)。
Arrays.toString(arr): 将数组转换为字符串表示形式,便于打印调试。
Arrays.asList(T... a): 返回一个固定大小的列表(List),由原数组生成。不能进行增删操作,否则会抛 UnsupportedOperationException。
高级与底层
协变数组
它允许你用一个子类型数组的引用赋值给一个父类型数组的变量。
1 | |
这种运行时错误是协变数组最大的缺陷。为了解决这个问题,Java语言的设计者在泛型(Generics)中引入了**不可变(Invariant)**的概念。
1 | |
其提供了编译时的类型安全保障,避免了运行时的类型转换错误。
链表
栈
队列
哈希表
使用一个Hash函数,将Key映射到存储位置Index的数据结构
哈希实现方法
☆哈希表如何解决哈希冲突:
1.链地址法:每个哈希桶存储一个链表(或其他结构),所有哈希到同一位置的元素都插入该链表。插入和查找时只需遍历链表即可。
1 | |
2.开放地址法:当发生冲突时,按照一定探查方式(如线性探查、二次探查、双重哈希)寻找下一个空位,将元素插入空位。查找时同样按探查顺序查找。
1 | |
3.再哈希法:发生冲突时,使用另一个哈希函数或者更大的表重新计算位置,直到找到空位。
- 扩容与重哈希:当哈希表负载因子过高时,扩容并重新分配所有元素,减少冲突概率。
- 双重哈希法:一个位置被占用时,不再简单地线性探测,而是通过另一个哈希函数决定跳步大小
$$
index = (hash_1(key) + i * hash_2(key))%M
$$
Java实现
Java的HashMap在JEP 180之前采用链表解决冲突,而之后当链表长度超过阈值(通常为8)通过将每个桶存储一个链表转为红黑树。
具体来说,当一个哈希桶中的链表长度达到 8(即 TREEIFY_THRESHOLD)时,并且此时哈希表的总容量(capacity)也达到了 64(即 MIN_TREEIFY_CAPACITY),这个链表就会被转换为一棵红黑树。
改进实现
在改进之前,字符串冲突的备选是采用hash32,为每一个String新增一个字段,此改进实现了任何Comparable接口的键类型的性能提升,字符串的hash32字段被移除。
该改进已经在java.util.concurrent.ConcurrentHashMap,HashMap以及LinkedHashMap中实现。但是在HashTable,WeakHashMap和IdentityHashMap中并不实现。
为什么要满足容量大于 64?
因为如果哈希表容量太小,频繁发生哈希冲突的原因很可能不是哈希函数不好,而是哈希表本身太小。在这种情况下,更好的解决办法是进行扩容(resize),而不是转换为红黑树。
当哈希表容量小于 64 时,即使链表长度达到了 8,HashMap 也会优先选择扩容,通过重新计算哈希值来分散元素。这样可以避免不必要的树化,减少性能开销。
为什么链表长度为8
泊松分布描述稀有事件在固定时间或者空间内发生的概率,适用于:
- 事件独立
- 事件发生的平均速率已知并固定
- 事件发生的概率极低
在哈希表中,设容量为m,插入n个键,每个键落入m个桶内,单个键冲突概率为$( \frac{1}{m})$
IdentityHashMap基于身份哈希的无冲突设计
IdentityHsahMap采用”==”而非”equals()”
HashMap
HashTable
WeakHashMap
WeakHashMap的弱引用与垃圾回收WeakHashMap 的核心特点是键(key)是弱引用。这意味着当一个键对象没有其他强引用指向它时,它随时可能被垃圾回收器(Garbage Collector, GC)回收。
WeakHashMap内部有一个ReferenceQueue队列维护被GC的键,当一个弱引用键被GC后,其会被添加到这个队列中,在每次put,get,remove时,会检查并清理这个队列,所有被GC的键从WeakHashMap中删除。因此带来了:
1) 红黑树的维护开销:红黑树在删除节点时会带来节点的旋转和重新着色。
2) GC行为无法预测:导致红黑树的结构也不可预测,会带来巨大的性能开销。
IdentityHashMap
IdentityHashMap采用”==”而不是”equals()”方法判断key是否相同
LinkedHashMap
底层实现为Hash表+双向链表
LRU缓存设计
Redis的LRU设计
redis的LRU并非严格LRU设计,而是近似的LRU设计,因为严格的LRU在每次访问一个键时需要将其移动到链表头部,同时对于内存和开销都有巨大压力:
EnumMap
ConcurrentSkipListMap
布谷鸟哈希
核心思想
一个键(key)在哈希表中有两个(或多个)可能的存放位置,由两个不同的哈希函数决定。就像一只布谷鸟蛋可以放在两个不同的巢中。
- 核心机制:“踢出”。当要插入一个新键时,如果它的两个位置都被占了,它不是去找下一个空位(像线性探测那样),而是随机选择其中一个位置,将占据该位置的老键踢出去,然后为这个被踢出的老键寻找它的另一个备选位置。这个过程可能会递归地进行,形成一连串的“踢出”操作。
工作流程
假设一个键 X有两个候选位置:h1(X)和 h2(X)。
- 插入:计算
h1(X)和h2(X)。如果两个位置有一个是空的,直接放入。如果两个位置都满了,随机选择一个(比如h1(X)),将占据该位置的老键Y踢出,将X放入。现在,为被踢出的Y寻找它的另一个家(即h2(Y))。如果h2(Y)是空的,放入。如果h2(Y)也被占了,重复上述“踢出”过程,直到所有键都安定下来,或者达到最大重试次数(此时需要扩容或重新构建哈希表)。 - 查找:极其高效。只需检查两个确定的位置
h1(X)和h2(X)。时间复杂度是严格的 O(1),没有链式遍历或长序列的探测。 - 删除:同样,检查两个位置,如果找到则删除。
优缺点
- 优点:超快查询:最坏情况下也只有两次内存访问,非常适合延迟敏感的应用。高负载因子:通过优化可以实现超过 90% 的空间利用率,而传统线性探测在 80% 时性能就已很差。
- 缺点:插入不稳定:插入操作可能在最坏情况下耗时很长(因为连续的踢出循环)。可能插入失败:即使表没满,也可能因为循环踢出而无法插入,需要扩容。
罗宾汉哈希
核心思想
在开放寻址法(如线性探测)的框架下,它通过比较键的“探测距离”来实现公平。
- 核心概念:探测距离:一个键的探测距离是指它从自己的初始哈希位置(由哈希函数计算得出)需要移动多少步(探测多少次)才找到现在这个位置。
- 核心机制:“劫富济贫”。当一个新的键要插入时,如果目标位置已被占用,它会比较自己当前的探测距离(此时为0)和该位置上老键的探测距离。如果新键的探测距离大于老键的探测距离(说明新键“更贫瘠”),它就有权“抢走”这个位置。老键被踢出,然后像新键一样继续为自己寻找新位置。否则,新键继续向后探测。
这个过程保证了所有键的“贫富差距”不会太大——即没有哪个键会离它的理想位置特别远。
工作流程(以线性探测为例)
- 插入键
X:计算初始位置pos = h(X),设置新键X的探测距离Dnew = 0。如果pos为空,直接插入。如果pos被键Y占据,获取Y的探测距离Dold。比较Dnew和Dold:如果Dnew > Dold(“新”的比“老”的更惨):将Y踢出,将X放入pos。然后被踢出的Y以Dold为起点,继续向后探测寻找新家。否则(Dnew <= Dold):X的Dnew加1,继续探测下一个位置。 - 查找与删除:与标准线性探测类似,但可以利用探测距离的信息进行优化(例如,如果当前探测距离已经大于正在查找的键的探测距离,说明它不可能在更远的位置,可提前结束)。
优缺点
- 优点:降低最坏情况:显著减少了长探测序列的发生,使所有操作的时间方差变小,性能更可预测。更高的平均负载因子:比传统开放寻址法能承受更高的负载。
- 缺点:实现更复杂:需要为每个槽存储键的探测距离信息。删除操作更麻烦:需要像线性探测一样使用“墓碑”标记。
Hopscotch Hashing(跳房子哈希)
Hopscotch Hashing 是一种基于线性探测的开放寻址法,它的核心目标是将每个键的探测序列长度控制在一个非常小的常数范围内,从而获得稳定、可预测的查询性能。
核心思想:邻域概念
它为每个哈希槽位 i定义了一个逻辑上的邻域。这个邻域包含了从 i开始向后连续的 H个槽位(例如 H=32,包含槽位 i到 i+31)。
- 核心规则:一个哈希值为
h(k)的键k,最终必须被存储在它的初始槽位h(k)的邻域内。 - 这保证了查找该键最多只需要检查
H个槽位,实现了 O(1) 的严格查询时间。
工作流程与关键操作
- 插入当试图将一个键
X插入到它的初始位置pos = h(X)时,如果该位置已被占用,插入过程不是简单地线性向后探测,而是包含一个关键的重排过程:- a) 顺序探测:从
pos开始,线性地向后查找,直到找到一个空槽。 - b) 检查距离:计算这个空槽到初始位置
pos的距离。如果这个距离小于邻域大小H(即空槽在邻域内),那么直接将X放入该空槽即可。 - c) 重排:如果空槽太远(距离 >=
H),就需要进行“跳房子”式的重排。算法会从空槽开始向前扫描(最多扫描H-1个槽位),寻找一个键Y。这个键Y需要满足一个条件:如果把它移动到后面的空槽,它仍然在自己的初始槽位的邻域内。找到这样的Y后,将Y移动到空槽中,此时Y原来的位置就变成了新的空槽。这个操作相当于让空槽向前“跳”了一步。重复这个过程,直到空槽被“搬运”到初始位置pos的邻域内,然后将X放入这个空槽。
- a) 顺序探测:从
- 查找仅在初始槽位
h(X)的邻域(H个槽位)内进行线性查找。因为规则保证了键一定在这个范围内。 - 删除找到并删除键,然后标记为“空”。
优缺点
- 优点:极佳的缓存局部性:由于键被限制在一个小邻域内,查找时内存访问集中,效率高。稳定的高性能:查询和插入在最坏情况下都是 O(1),因为只与常数
H有关。 - 缺点:插入可能失败:即使表中有空位,但如果无法通过重排将空槽移入邻域,插入仍然会失败,需要扩容。实现稍复杂:重排逻辑比简单的线性探测复杂。
Extendible Hashing(可扩展哈希)
Extendible Hashing 是为磁盘等外部存储设计的哈希方法,其核心目标是在数据量增长时最小化磁盘I/O次数。它通过一种“目录”机制来实现动态的、平滑的扩容。
核心组件
- 目录:一个在内存中维护的数组,每个目录项是一个指针,指向一个页(桶)。目录的大小是 2^G,其中
G称为全局深度。 - 页(桶):实际存储键值对的数据块(通常对应一个磁盘页)。每个页有一个局部深度
L,满足L <= G。
工作流程
- 哈希计算:对键
k计算哈希值h(k),然后取这个哈希值的后G位(全局深度位)作为目录索引。例如,G=3,就取后3位,目录有8项。 - 查找:根据后
G位找到目录项,然后访问该目录项指向的页,在页内进行线性查找。只需一次磁盘I/O。 - 插入与分裂(核心):找到键对应的页。如果页内还有空间,直接插入。如果页已满,则需要页分裂:a. 增加该页的局部深度
L(例如从1增加到2)。b. 创建一个新页。c. 将原页中的所有键重新哈希,根据它们哈希值的第L位(新增加的这一位)进行分配。位为0的留在原页,位为1的移到新页。d. 更新目录:因为全局深度G可能等于或大于新的局部深度L。算法需要确保所有索引位后L位与原页相同的目录项都指向原页,所有索引位后L位与新页相同的目录项都指向新页。情况一:L <= G。只需更新部分目录指针。这是最常见的情况,扩容非常高效。情况二:L > G。这意味着目录需要翻倍(目录扩容)。将G加1,目录大小翻倍,然后重新设置所有目录项的指针。
优缺点
- 优点:高效扩容:扩容时通常只需要分裂一个满的页,而不是重建整个表,成本低。一次磁盘访问:在任何情况下,查找一个键都只需要一次磁盘I/O(因为目录在内存中,能直接定位到正确的页)。
- 缺点:目录可能很大:当数据量非常大时,目录本身可能变得很大,虽然它在内存中,但仍是一种开销。空间可能浪费:如果数据分布不均,多个目录项可能指向同一个页,造成目录空间浪费。
进阶数据结构
堆
优先队列
普通队列按照先进先出的方式出入队。
优先队列则是 按照元素的优先级出队,而不是进入的先后顺序。
Java中实现了PriorityQueue<E>的方法,默认为最小堆。
1 | |
可以传入自定义的比较器
1 | |
应用场景
- 任务调度:高优先级任务先执行。
- Dijkstra 最短路径算法:每次取“当前距离最小的点”。
- Huffman 编码:每次合并权值最小的两棵树。
- Top-K 问题:找出最大的 K 个元素。
TreeMap
Deque 双端队列
TreeSet
图
并查集DSU
高级数据结构
跳表
线段树
前缀树
AVL
红黑树
布隆过滤器
布隆过滤器是一种空间效率极高的概率型数据结构,用于判断一个元素是否在集合中。它通过多个哈希函数将元素映射到位数组的不同位置,插入时将对应位设为1,查询时只要有一个位为0则一定不在集合中,否则可能在集合中(存在误判)。
优点:
- 占用空间小,插入和查询速度快。
- 适合大数据场景下的快速去重和存在性判断。
缺点:
- 存在一定的误判率(假阳性),无法删除元素(标准实现)。
- 不支持元素的遍历。
应用场景:
- 数据库缓存过滤(如Redis缓存穿透防护)
- 网络黑名单检测
- 大规模去重(如爬虫URL判重)
时间复杂度:
- 插入操作(Add): O(K)
- 查询操作(Check): O(K)
k是哈希函数的数量
Java实现
1 | |
第三方库
1 | |
有序哈希表LinkedHashMap
WeakHashMap
EnumSet
EnumMap
地址哈希表IdentityHashMap
ConcurrentHashMap
时间轮Time Wheel
位图BitMap
BitMap是一段把二进制位当做String来操作的一组位操作接口。例如要存储列
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
|---|
位集 BitSet
是对位图的一种抽象/封装。
在 Java 里,
java.util.BitSet是一个类,内部本质上就是用long[]存储位,但对外暴露了更友好的 API(如set(),get(),clear(),and(),or()等)。强调的是「集合语义」——把每个 bit 看作集合元素的 membership。
java中的BitSet采用Long[]实现,其索引是int型,即最大值在2^31-1,约为21亿。
BitMap最常用的方法是